
In un recente studio pubblicato sulla rivista Medicina digitale NPJi ricercatori hanno utilizzato un set di dati dell'accelerometro su larga scala della Biobank del Regno Unito costituito da dati de-etichettati per 700.000 giorni lavorativi per costruire modelli per monitorare i livelli di attività fisica con maggiore precisione e generalizzabilità.
Soggiorno: Apprendimento autosupervisionato per riconoscere l'attività umana utilizzando 700.000 giorni di dati indossabili. Credito immagine: sotademages/Shutterstock
sfondo
Il settore sanitario ha assistito a un rapido aumento nello sviluppo e nell’utilizzo di dispositivi indossabili con sensori che possono essere utilizzati per il monitoraggio della salute e del fitness, il monitoraggio remoto dei pazienti, studi clinici che richiedono dati in tempo reale, rilevamento precoce delle malattie e medicina personalizzata. Condurre studi sanitari su larga scala. Questi dispositivi forniscono misure riassuntive di mobilità, qualità del sonno, conteggio dei passi, andatura e tempo di seduta. Tuttavia, sono necessari algoritmi affidabili per ottenere informazioni sull’attività umana dai dati raccolti dal sensore.
Mentre campi come l’elaborazione del linguaggio naturale e la visione artificiale hanno fatto grandi progressi grazie alla disponibilità di dati in eccesso per addestrare questi modelli di apprendimento, la scarsità di set di dati su larga scala che possono essere utilizzati per addestrare algoritmi ha ostacolato il progresso nello sviluppo di modelli che possano essere affidabili e affidabili. riconoscere con precisione l’attività umana. La mancanza di dati sufficienti per addestrare questi modelli ha anche confuso i risultati relativi ai modelli di deep learning, suggerendo che i modelli di deep learning non funzionano meglio dei metodi tradizionali come le semplici statistiche.
A proposito dello studio
Nel presente studio, i ricercatori hanno utilizzato un set di dati dell’accelerometro della Biobank del Regno Unito per addestrare modelli di deep learning a riconoscere con precisione l’attività fisica. La Biobanca britannica ha condotto uno studio sull’accelerometro su larga scala reclutando quasi mezzo milione di partecipanti. Più di centomila di questi partecipanti hanno indossato un accelerometro al polso per una settimana nel loro ambiente naturale, piuttosto che in un ambiente di laboratorio. Ciò ha fornito circa 700.000 giorni di dati sui movimenti umani in vita libera.
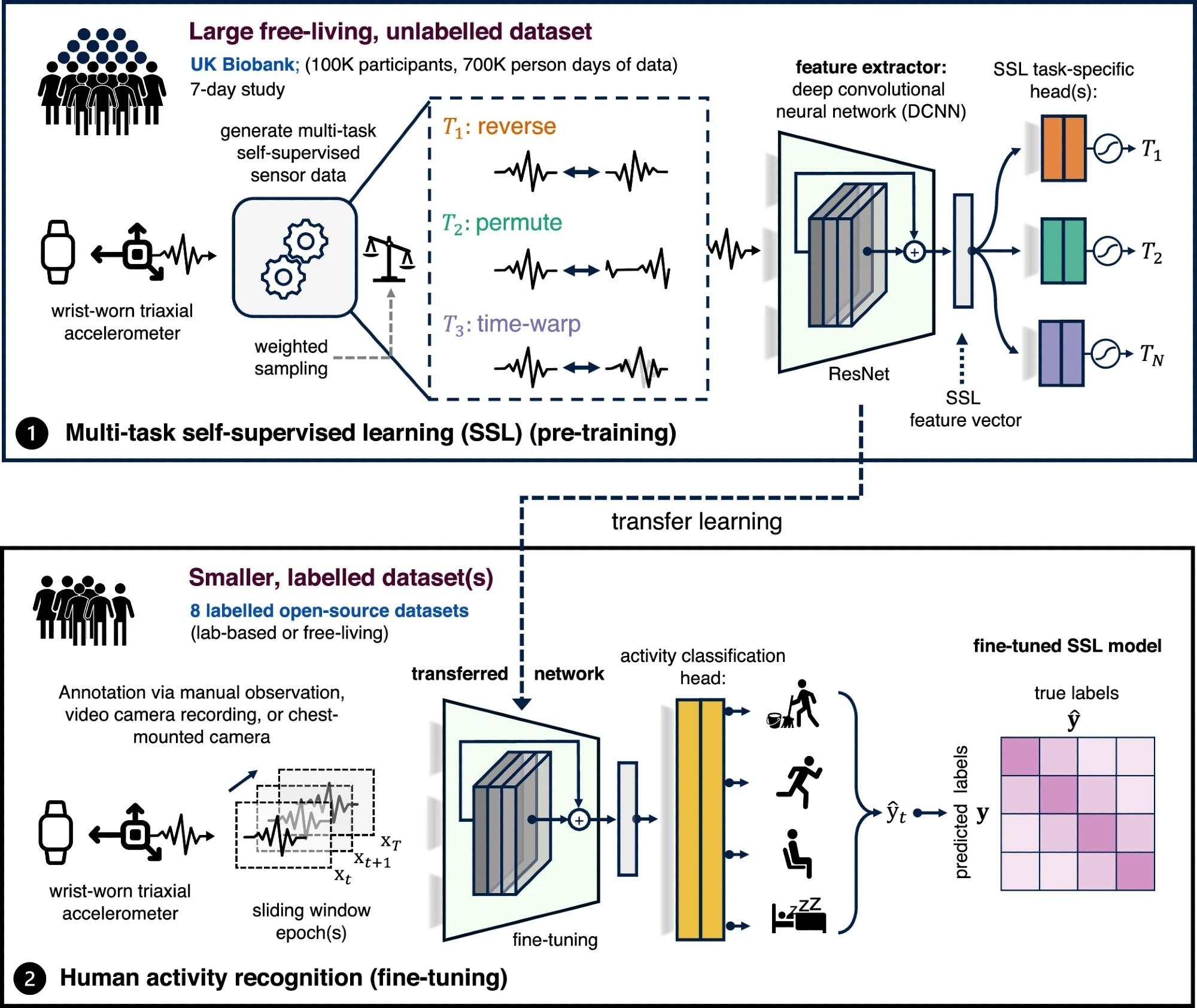 Panoramica della proposta pipeline di apprendimento autosupervisionato. Il primo passo prevede l'apprendimento multitasking autosupervisionato su 700.000 giorni lavorativi di dati provenienti dalla biobanca del Regno Unito. Nella fase 2, valutiamo l'utilità della rete pre-addestrata su otto linee di riferimento di riferimento per il riconoscimento dell'attività umana attraverso l'apprendimento del trasferimento.
Panoramica della proposta pipeline di apprendimento autosupervisionato. Il primo passo prevede l'apprendimento multitasking autosupervisionato su 700.000 giorni lavorativi di dati provenienti dalla biobanca del Regno Unito. Nella fase 2, valutiamo l'utilità della rete pre-addestrata su otto linee di riferimento di riferimento per il riconoscimento dell'attività umana attraverso l'apprendimento del trasferimento.
I ricercatori hanno utilizzato un approccio di apprendimento auto-supervisionato, che è stato utilizzato con successo per esempi come Generative Pre-Trained Transformers o GPT. Studi recenti hanno utilizzato diversi metodi di apprendimento autosupervisionato come la ricostruzione mascherata, l'autosupervisione multi-task, il bootstrap e l'apprendimento divergente per esaminare l'analisi dei dati dai sensori indossabili. Il presente studio ha applicato un metodo di autosupervisione multi-task a un ampio set di dati di una biobanca del Regno Unito per mostrare come un modello pre-addestrato può essere generalizzato a un’ampia gamma di set di dati basati sull’attività di interesse sanitario e clinico.
Il metodo di apprendimento autosupervisionato multi-task è stato applicato per la prima volta a un set di dati di un accelerometro su larga scala della Biobank del Regno Unito per addestrare una rete neurale convoluzionale profonda. Successivamente, sono stati utilizzati otto set di dati di riferimento per valutare le prestazioni della rete neurale pre-addestrata e valutare la qualità della rappresentazione su diverse popolazioni e tipi di attività.
Sono stati utilizzati set di dati etichettati per valutare il successo del modello nel trasferimento dell'apprendimento. Inoltre, lo studio ha utilizzato anche un approccio di campionamento ponderato per aggirare il problema dei periodi non informativi di scarsa mobilità. I dati del mondo reale raccolti dai sensori di movimento hanno periodi di inattività e tali segnali statici non cambiano durante la conversione, il che presenta problemi per le attività di apprendimento auto-supervisionate. Pertanto, per migliorare la convergenza e la stabilità del processo di formazione, i ricercatori hanno applicato un approccio di campionamento ponderato in cui le finestre di dati sono state campionate proporzionalmente e la deviazione standard di tali campioni è stata utilizzata per l’analisi.
risultati
I risultati hanno mostrato che quando i modelli addestrati in questo studio sono stati testati su otto set di dati di riferimento, hanno sovraperformato i valori di base con un miglioramento relativo medio del 24,4%. Inoltre, il modello può essere generalizzato a un’ampia gamma di sensori di movimento, ambienti di vita, gruppi e set di dati esterni.
L’approccio pre-formazione multi-task autosuperato si è rivelato efficace anche nel migliorare il riconoscimento dell’attività umana, anche su piccoli set di dati non etichettati. Anche la pre-formazione autosupervisionata può offrire risultati migliori rispetto al metodo supervisionato.
I ricercatori hanno affermato che questo studio ha dimostrato che il metodo autosupervisionato dell’apprendimento multi-task può essere applicato a set di dati provenienti da sensori indossabili e costruire modelli accurati e generalizzabili di riconoscimento delle attività utilizzando algoritmi di deep learning.
Il team di ricerca ha inoltre rilasciato i modelli pre-addestrati alla comunità di ricerca che lavora nel campo della salute digitale, in modo che sulla base di essi possano essere costruiti modelli ad alte prestazioni da utilizzare in vari altri campi che coinvolgono dati etichettati limitati.
Conclusioni
Per riassumere, lo studio ha utilizzato un set di dati su larga scala e senza etichetta della Biobank del Regno Unito, costituito da dati dell’accelerometro per pre-addestrare modelli di deep learning attraverso un approccio auto-supervisionato. Le prestazioni di questi modelli pre-addestrati andavano oltre i livelli di base nell’analisi dettagliata dei dati dei sensori di movimento su diversi set di dati in cluster, sensori e ambienti di vita. I ricercatori ritengono che questi modelli possano essere sviluppati e utilizzati in vari scenari che coinvolgono quantità limitate di dati etichettati.
Riferimento alla rivista:
- Yuan, H., Chan, S., Creagh, A. P., Tong, C., Acquah, A., Clifton, D. A., & Doherty, A. (2024). Apprendimento autocontrollato per riconoscere l'attività umana utilizzando 700.000 giorni di dati indossabili. Medicina digitale Npj7(1), 91. DOI: 10.1038/s41746024010623, https://www.nature.com/articles/s41746-024-01062-3

“Pluripremiato specialista televisivo. Appassionato di zombi. Impossibile scrivere con i guantoni da boxe. Pioniere di Bacon.”




More Stories
Spiagge finte si stanno diffondendo su Internet e la colpa è dei giocatori di Pokémon Go
L’adesivo “Aggiungi il tuo” di Instagram ora ti consente di condividere brani
Un nuovo metodo di modellazione di stacking bayesiano non negativo per prevedere la sopravvivenza del cancro utilizzando dati omici ad alta dimensione Metodologia della ricerca medica BMC